Langfuse Tutorial: LLM Observability & Evaluation

This is a getting-started tutorial on Langfuse, the open-source LLM engineering platform. This notebook covers all essential concepts you need to get started with LLM observability, evaluation, and prompt management.
What is Langfuse?
Langfuse is an open-source platform that helps teams:
- Observe LLM applications through detailed tracing
- Evaluate model performance with various scoring methods
- Manage prompts collaboratively with version control
- Debug and improve LLM applications in production
Key Features We'll Cover
- Setup & Basic Tracing - Get started with observability
- LLM Integration - Integrate with OpenAI and capture usage
- Prompt Management - Version and manage prompts centrally
- Evaluation & Scoring - Assess model quality with various methods
- Datasets - Create test sets for systematic evaluation
- Analytics - Monitor performance and gather insights
1. Setup and Installation
First, let's install the required packages and set up our environment.
# Install required packages
# !pip install langfuse openai python-dotenv -qimport os
from langfuse import Langfuse, observe
from langfuse.openai import openai # Langfuse OpenAI integration
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
LANGFUSE_PUBLIC_KEY = os.getenv("LANGFUSE_PUBLIC_KEY")
LANGFUSE_SECRET_KEY = os.getenv("LANGFUSE_SECRET_KEY")
LANGFUSE_HOST = os.getenv("LANGFUSE_HOST")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# Initialize Langfuse client
langfuse = Langfuse()
# Test connection
print("✅ Langfuse connection:", langfuse.auth_check())
print("📍 Using Langfuse host:", LANGFUSE_HOST)✅ Langfuse connection: True 📍 Using Langfuse host: https://cloud.langfuse.com
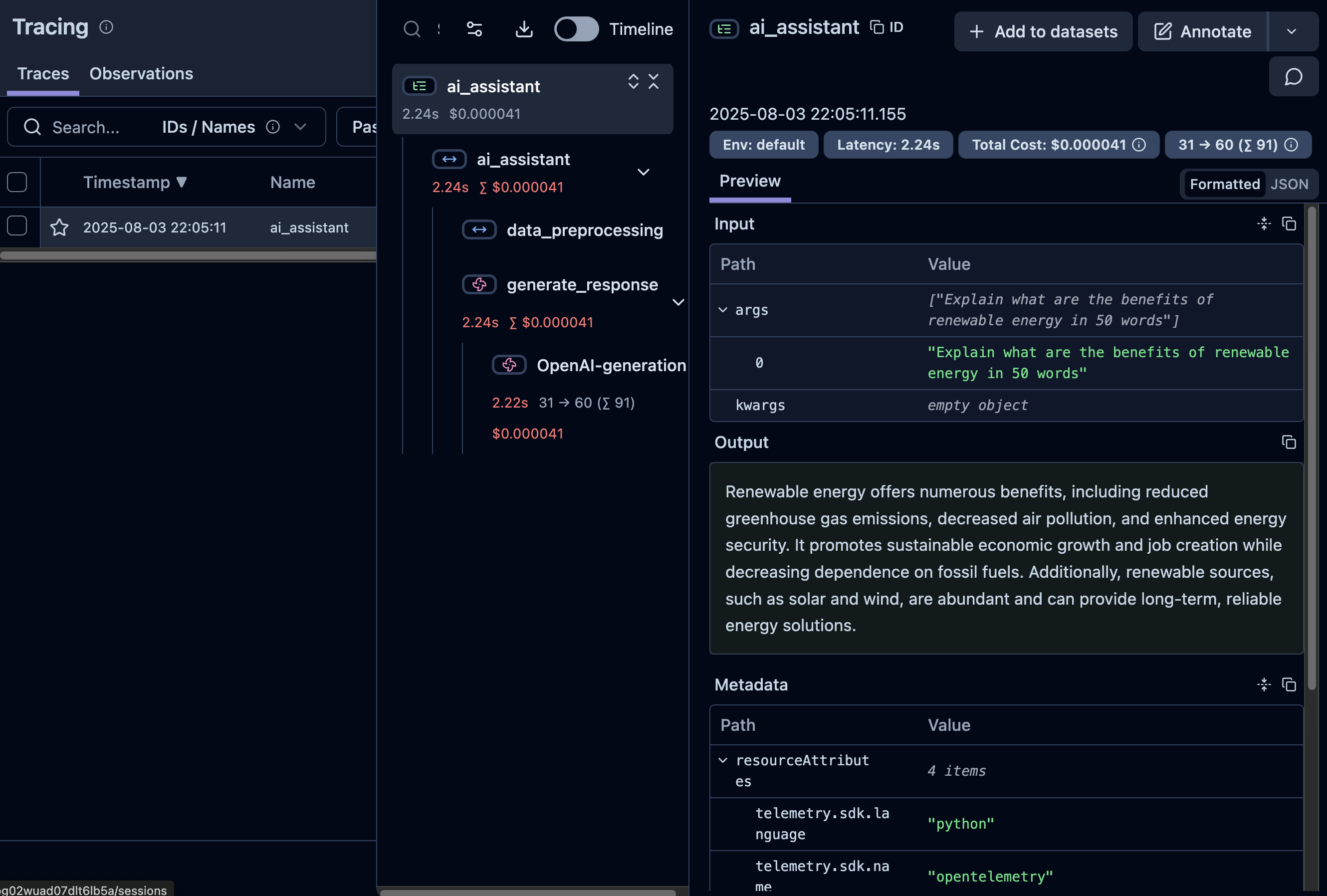
2. Basic Tracing with Decorators
The @observe() decorator is the simplest way to add observability to your functions. It automatically creates traces and spans.
@observe()
def data_preprocessing(text: str):
"""Simulate data preprocessing step"""
cleaned_text = text.strip().lower()
return cleaned_text
@observe(as_type="generation")
def generate_response(prompt: str):
"""Generate AI response using OpenAI"""
response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": prompt}
],
temperature=0.7,
max_tokens=150
)
return response.choices[0].message.content
@observe()
def ai_assistant(user_input: str):
"""Main AI assistant function"""
# Process input and generate response
processed_input = data_preprocessing(user_input)
response = generate_response(processed_input)
return response
# Test the traced function
result = ai_assistant("Explain what are the benefits of renewable energy in 50 words")
print("AI Response:", result)AI Response: Renewable energy offers numerous benefits, including reduced greenhouse gas emissions, decreased air pollution, and enhanced energy security. It promotes sustainable economic growth and job creation while decreasing dependence on fossil fuels. Additionally, renewable sources, such as solar and wind, are abundant and can provide long-term, reliable energy solutions.
3. Prompt Management
Langfuse allows you to manage prompts centrally with version control and collaborative editing.
# Create a managed prompt
langfuse.create_prompt(
name="content-summarizer",
prompt="You are an expert content summarizer. Summarize the following text in {{max_words}} words, focusing on {{focus_area}}.\n\nText: {{content}}",
config={
"model": "gpt-4o-mini",
"temperature": 0.3,
"max_tokens": 200
},
labels=["production"] # Mark as production version
)
@observe()
def summarize_content(content: str, max_words: int = 50, focus_area: str = "key insights"):
"""Summarize content using managed prompt"""
# Get the current prompt version
prompt = langfuse.get_prompt("content-summarizer")
# Format prompt with variables
formatted_prompt = prompt.prompt.replace("{{content}}", content)
formatted_prompt = formatted_prompt.replace("{{max_words}}", str(max_words))
formatted_prompt = formatted_prompt.replace("{{focus_area}}", focus_area)
# Use prompt config for model parameters
response = openai.chat.completions.create(
model=prompt.config["model"],
messages=[{"role": "user", "content": formatted_prompt}],
temperature=prompt.config["temperature"],
max_tokens=prompt.config["max_tokens"]
)
return response.choices[0].message.content
# Test prompt management
sample_text = "Artificial intelligence is transforming industries worldwide. Machine learning algorithms enable computers to learn from data without explicit programming. Deep learning, a subset of ML, uses neural networks to solve complex problems. Applications include image recognition, natural language processing, and autonomous vehicles."
summary = summarize_content(sample_text, max_words=10, focus_area="technological impact")
print("Summary:", summary)Summary: AI revolutionizes industries through machine learning and deep learning applications.
4. Evaluation and Scoring
Langfuse supports various evaluation methods including custom scores, user feedback, and LLM-as-a-judge.
@observe()
def evaluate_response_quality(original_text: str, summary: str):
"""Evaluate summary quality using LLM-as-a-judge"""
# LLM-as-a-judge evaluation
eval_prompt = f"""
Evaluate the quality of this summary on a scale of 1-10:
Original Text: {original_text}
Summary: {summary}
Rate the summary based on:
- Accuracy (captures key information)
- Conciseness (appropriate length)
- Clarity (easy to understand)
Respond with only a number from 1-10.
"""
eval_response = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": eval_prompt}],
temperature=0.1
)
try:
quality_score = float(eval_response.choices[0].message.content.strip())
except ValueError:
quality_score = 5.0 # Default score if parsing fails
return quality_score
@observe()
def comprehensive_ai_pipeline(user_input: str):
"""Complete AI pipeline with evaluation"""
# Generate summary
summary = summarize_content(user_input, max_words=40)
# Evaluate quality
quality_score = evaluate_response_quality(user_input, summary)
# Add custom scores to the trace using the correct Langfuse 3.2.1 API
langfuse.score_current_trace(
name="quality",
value=quality_score,
comment=f"LLM-as-a-judge quality evaluation"
)
# Add custom metrics
word_count_score = len(summary.split())
langfuse.score_current_trace(
name="word_count",
value=word_count_score,
comment="Number of words in summary"
)
# Simulate user feedback (in practice, this would come from your app)
user_rating = 4 # Scale of 1-5
langfuse.score_current_trace(
name="user_satisfaction",
value=user_rating,
comment="Simulated user feedback"
)
return {
"summary": summary,
"quality_score": quality_score,
"word_count": word_count_score,
"trace_id": langfuse.get_current_trace_id()
}
# Test evaluation pipeline
sample_article = "Climate change is one of the most pressing challenges of our time. Rising global temperatures are causing ice caps to melt, sea levels to rise, and weather patterns to become more extreme. Renewable energy sources like solar and wind power offer sustainable alternatives to fossil fuels. Governments and businesses worldwide are investing in clean technology to reduce carbon emissions and mitigate environmental impact."
result = comprehensive_ai_pipeline(sample_article)
print("Results:")
for key, value in result.items():
print(f"{key}: {value}")Results: summary: Climate change poses significant challenges, including rising temperatures, melting ice caps, and extreme weather. Renewable energy sources like solar and wind power provide sustainable alternatives to fossil fuels, with global investments in clean technology aimed at reducing carbon emissions and environmental impact. quality_score: 9.0 word_count: 42 trace_id: ff8e2ba59f681fcd6943f24d08a769e2
5. Datasets for Testing
Create datasets to systematically test your LLM applications and track performance over time.
# Create a dataset for testing
dataset_name = "text-summarization-test"
# Create dataset
langfuse.create_dataset(
name=dataset_name,
description="Test cases for text summarization quality",
metadata={"version": "1.0", "purpose": "quality_testing"}
)
# Add test cases to dataset
test_cases = [
{
"input": "Machine learning is a subset of artificial intelligence that enables computers to learn and make decisions from data without being explicitly programmed. It involves algorithms that can identify patterns and make predictions.",
"expected_output": "Machine learning uses algorithms to help computers learn from data and make predictions without explicit programming."
},
{
"input": "The human brain contains approximately 86 billion neurons that communicate through electrical and chemical signals. These neural networks process information and enable cognitive functions like memory, learning, and decision-making.",
"expected_output": "The brain has 86 billion neurons that communicate via signals to enable cognitive functions like memory and learning."
},
{
"input": "Renewable energy sources such as solar, wind, and hydroelectric power are becoming increasingly important as alternatives to fossil fuels. They offer sustainable solutions to meet growing energy demands while reducing environmental impact.",
"expected_output": "Solar, wind, and hydroelectric power are sustainable renewable energy alternatives to fossil fuels with less environmental impact."
}
]
# Add items to dataset
for i, case in enumerate(test_cases):
langfuse.create_dataset_item(
dataset_name=dataset_name,
input=case["input"],
expected_output=case["expected_output"],
metadata={"test_case_id": i+1}
)
@observe()
def run_dataset_evaluation():
"""Run evaluation on dataset items"""
results = []
for case in test_cases:
# Generate summary
generated_summary = summarize_content(case["input"], max_words=25)
# Compare with expected output (simple similarity check)
expected_words = set(case["expected_output"].lower().split())
generated_words = set(generated_summary.lower().split())
# Calculate word overlap similarity
intersection = expected_words.intersection(generated_words)
union = expected_words.union(generated_words)
similarity = len(intersection) / len(union) if union else 0
# Score the result using the correct Langfuse 3.2.1 API
langfuse.score_current_trace(
name="similarity_score",
value=similarity,
comment=f"Word overlap similarity with expected output"
)
results.append({
"input": case["input"][:50] + "...",
"generated": generated_summary,
"expected": case["expected_output"],
"similarity": round(similarity, 3)
})
return results
# Run dataset evaluation
eval_results = run_dataset_evaluation()
print("Dataset Evaluation Results:")
for i, result in enumerate(eval_results, 1):
print(f"\nTest Case {i}:")
print(f"Input: {result['input']}")
print(f"Generated: {result['generated']}")
print(f"Similarity: {result['similarity']}")Dataset Evaluation Results: Test Case 1: Input: Machine learning is a subset of artificial intelli... Generated: Machine learning, a subset of artificial intelligence, allows computers to learn from data and make decisions using algorithms that identify patterns and predictions. Similarity: 0.31 Test Case 2: Input: The human brain contains approximately 86 billion ... Generated: The human brain has about 86 billion neurons that communicate via signals, facilitating cognitive functions such as memory, learning, and decision-making. Similarity: 0.444 Test Case 3: Input: Renewable energy sources such as solar, wind, and ... Generated: Renewable energy sources like solar, wind, and hydroelectric power are vital alternatives to fossil fuels, providing sustainable solutions to rising energy demands and minimizing environmental impact. Similarity: 0.538
Summary
🎉 Congratulations! You've completed the comprehensive Langfuse tutorial. Here's what you've learned:
Key Concepts Covered:
- Setup & Basic Tracing - Using
@observe()decorators for automatic observability - LLM Integration - Seamless OpenAI integration with usage tracking
- Prompt Management - Centralized prompt versioning and configuration
- Evaluation & Scoring - Multiple evaluation methods including LLM-as-a-judge
- Datasets - Creating test sets for systematic quality assessment
- Analytics - Performance monitoring and insights
Next Steps:
- Visit your Langfuse dashboard to see your traces
- Explore advanced features like custom evaluators and production monitoring
- Integrate with your existing LLM applications using the patterns learned here
Happy building! 🚀